

A tiny mistake inside a URL can wreck an entire request. One misplaced symbol, one broken percent sign, or one incorrectly encoded character may trigger a 400 Bad Request, break a checkout page, corrupt Query Parameters, or destroy tracking data before it even reaches your analytics dashboard.
That sounds dramatic until you see it happen in production.
Many developers discover URL Encoding issues only after users start reporting broken links, failed redirects, or missing search results. Sometimes the damage stays hidden for weeks. A malformed Request URL can quietly confuse Search Engine Crawlers, waste Crawl Budget, and weaken overall Search Visibility without obvious warning signs.
The phrase “url encoder spellmistake” often appears when people search for strange encoding behavior, corrupted URLs, or failed decoding attempts. In reality, these problems usually stem from incorrect Percent-Encoding, broken Parsing Logic, invalid Hexadecimal Digits, or inconsistent encoding rules across systems.
This guide breaks everything down in plain English. No robotic explanations. No filler. Just practical insight into how modern web systems handle URLs and why encoding mistakes create chaos faster than most teams expect.
What Is a URL Encoder Spell Mistake?
A URL Encoder Spell Mistake usually refers to an incorrectly encoded URL component. The issue may look like a typo on the surface, yet the real problem often sits deeper inside the encoding structure itself.
For example, imagine someone manually edits a URL and changes %20 into %2G. That tiny change creates an invalid sequence because G is not a valid hexadecimal character. The browser tries to process it anyway. The server receives corrupted data. Suddenly your clean URL turns into a Syntax Error waiting to happen.
In other cases, the issue appears during Manual URL Construction. Developers concatenate strings together without using proper encoding utilities. A product name like “Dolce & Gabbana” becomes problematic because the ampersand behaves as a parameter separator inside a URL.
Broken URL:
example.com/search?q=Dolce & Gabbana
The browser interprets that ampersand as a split between parameters. The intended search query gets destroyed halfway through transmission.
A correctly encoded version looks like this:
Correct URL:
example.com/search?q=Dolce%20%26%20Gabbana
This is where URL Encoder, URL Decoding, and URIComponent functions become critical. Proper encoding protects the integrity of data during Payload Transmission across browsers, APIs, proxies, and backend systems.
Why Correct URL Encoding Matters in Modern Web Systems
URLs are more than clickable links. They function as communication channels between browsers, servers, APIs, databases, and distributed services.
Every HTTP Request depends on clean formatting. If the URL structure breaks, the request itself becomes unreliable. A malformed query string can prevent a REST API endpoint from recognizing incoming data. A corrupted redirect URL may invalidate session handling or destroy tracking attribution.
This becomes especially dangerous inside large-scale systems using:
- Microservices
- API Gateway routing
- CDN edge caching
- Dynamic frontend frameworks
- Stateful authentication flows
Even a single encoding inconsistency can ripple through the entire Encoding Pipeline.
Search engines also care deeply about URL consistency. Googlebot expects deterministic URLs with stable formatting. If multiple encoded variations point to identical pages, crawlers may waste time indexing duplicates instead of discovering important content.
That weakens:
- Domain Authority
- Crawl efficiency
- Internal linking structure
- Canonical signal clarity
- Overall Search Engine Optimization
A surprising number of SEO problems start with poor URL hygiene rather than content quality.
Understanding How URL Encoding Actually Works

At its core, URL Encoding converts unsafe characters into a web-safe format that browsers and servers can reliably understand.
The internet originally relied on the ASCII Character Set, which supported only a limited range of characters. Modern websites use Unicode, emojis, multilingual text, and special symbols. Browsers therefore need a standard method to transmit these characters safely through URLs.
That standard comes from RFC 3986, maintained by the Internet Engineering Task Force.
The process works through Percent-Encoding.
Here is a simple example:
| Character | Encoded Value |
|---|---|
| Space | %20 |
& | %26 |
? | %3F |
# | %23 |
Each encoded value contains:
- A percent sign
- Two Hexadecimal Digits
- A byte representation of the original character
For example:
Space → %20
The hexadecimal value 20 represents a space character in ASCII.
This matters because URLs contain Reserved Characters with special meanings inside the URI Protocol. Characters like ?, &, and = control parameter structure. If they remain unencoded in the wrong place, browsers misinterpret the entire URL.
That’s why encoding exists in the first place. It preserves structure while safely transmitting dynamic data.
The Difference Between URL Encoding and URL Decoding
People often mix these concepts together. They are related, yet they perform opposite tasks.
URL Encoding converts unsafe text into transport-safe values. URL Decoding restores those encoded values back into readable characters.
For example:
Encoded:
hello%20world
Decoded:
hello world
Encoding happens before transmission. Decoding happens after receipt.
Problems emerge when systems accidentally decode data multiple times. This leads to Double Encoding and even Recursive Double-Encoding, which can quietly break routing behavior.
Imagine this sequence:
Original:
hello world
Encoded:
hello%20world
Double Encoded:
hello%2520world
The second encoding transforms % into %25.
That tiny detail creates massive confusion inside Backend Router logic and API validation systems.
Common Causes of URL Encoder Spellmistake Problems
Most encoding issues do not happen because developers lack intelligence. They happen because modern systems are layered, distributed, and surprisingly fragile.
One of the biggest causes involves inconsistent encoding behavior between frontend and backend systems. A Frontend Client may encode data one way while a Backend Server expects another format entirely.
A React application, for instance, may use encodeURIComponent() correctly while a legacy PHP backend applies urlencode() again during processing. Suddenly the application produces double-encoded URLs.
Another major cause involves copy-pasting URLs from rich text editors like Microsoft Word. Smart quotes, invisible formatting marks, and hidden Unicode artifacts often sneak into URLs unnoticed.
Developers also run into problems when handling:
- File paths
- UTM tracking parameters
- Search queries
- API payloads
- Session tokens
- E-commerce filtering facets
Complex query strings increase the risk of malformed encoding exponentially.
Then there’s the human factor.
Many teams still rely on raw string concatenation during URL Construction. That approach looks quick during development yet creates brittle systems later.
const url = "/search?q=" + query;
This works until the query contains special characters.
The Hidden SEO Damage Caused by Encoding Errors
SEO teams often focus heavily on backlinks and content quality. Meanwhile encoding problems quietly sabotage site performance behind the scenes.
Improper URL formatting can create duplicate URLs that point to identical pages. Search engines then split ranking signals between variations.
For example:
/page-name
/page%2Dname
/page%252Dname
These may appear identical to users while search crawlers treat them differently.
Over time, this causes:
- Duplicate indexing
- Fragmented authority
- Weak crawl efficiency
- Confused canonicalization
- Broken deep linking
Large ecommerce sites face even greater risk. Product filters generate thousands of dynamic URLs using faceted navigation systems.
Without proper encoding rules, Search Engine Crawlers may waste enormous portions of the site’s Crawl Budget on malformed parameter combinations.
That creates indexing bottlenecks. Important pages remain undiscovered while useless URL variations flood the crawl path.
Technical SEO audits frequently uncover these issues inside:
- Infinite filter URLs
- Broken pagination
- Tracking parameters
- Dynamic search URLs
- Internal redirects
Encoding mistakes rarely stay isolated. They spread across entire site architectures.
Real Examples of URL Encoding Mistakes and Fixes

Sometimes the easiest way to understand encoding problems is through real-world examples.
Spaces Inside Search Queries
A user searches for “wireless headphones.”
Broken version:
example.com/search?q=wireless headphones
Correct version:
example.com/search?q=wireless%20headphones
The browser may auto-correct this sometimes, yet relying on browser behavior creates inconsistent results across systems.
Ampersands Breaking Parameters
This issue appears constantly in ecommerce systems.
Broken URL:
?q=Dolce & Gabbana
The ampersand splits the parameter unintentionally.
Correct version:
?q=Dolce%20%26%20Gabbana
Now the entire phrase stays intact during Data Transmission.
Broken UTF-8 Characters
International text creates another layer of complexity.
Broken:
café
Correct:
caf%C3%A9
Without proper UTF-8 handling, systems may generate unreadable Unicode Artifacts or routing failures.
Recursive Double-Encoding
This problem becomes extremely difficult to debug inside distributed environments.
Broken:
redirect%252Fdashboard
Correct:
redirect%2Fdashboard
One encoding pass is enough. Multiple encoding layers corrupt the routing structure.
How Developers Identify URL Encoding Problems
Encoding issues rarely announce themselves clearly. Most developers first notice indirect symptoms.
A checkout page suddenly fails. API responses return strange status codes. Authentication redirects stop working. Analytics tracking disappears without explanation.
The first place experienced engineers investigate is the browser network inspector.
Inside Chrome Developer Tools, the Browser Network Tab reveals:
- Raw request URLs
- Encoded payloads
- Redirect chains
- Response headers
- Failed network requests
This makes Differential Analysis much easier. Developers compare working requests against broken ones to isolate malformed encoding patterns.
Monitoring tools also help significantly. Platforms like Sentry and Datadog often expose malformed URLs inside error logs before users report them publicly.
Backend systems provide another critical clue.
Reviewing:
- Server Logs
- Access Logs
- Proxy logs
- CDN request traces
can reveal invalid byte structures or repeated decoding attempts.
Sometimes the issue originates upstream inside a WAF (Web Application Firewall) or load balancer rather than the application itself.
That’s why debugging encoding problems requires a full-system perspective.
URL Encoding in APIs and Backend Systems
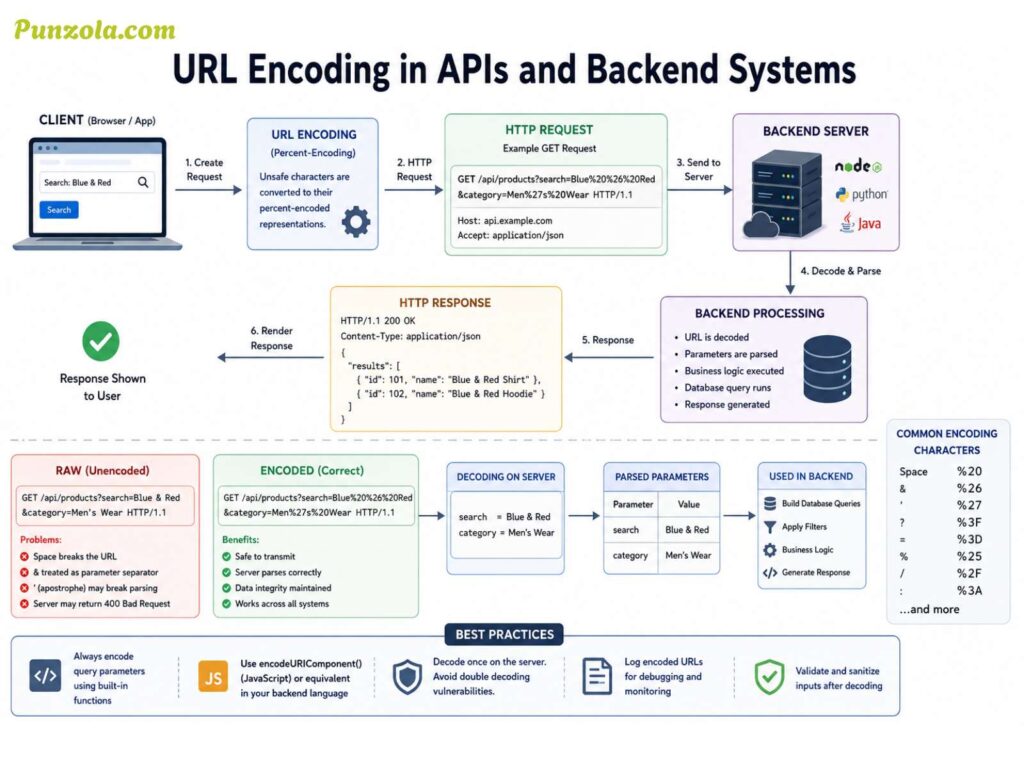
Modern APIs depend heavily on predictable URL formatting.
A malformed endpoint signature can cause an entire REST API to reject requests even when authentication works perfectly.
Imagine this API endpoint:
/api/products?category=smart watches
The space creates ambiguity during routing.
Correct version:
/api/products?category=smart%20watches
Now the backend receives clean, deterministic data.
Encoding problems become even more dangerous inside authentication systems. OAuth redirect URIs, token callbacks, and session validation depend on exact URL matching.
One mismatched encoded character may invalidate:
- Session tokens
- API signatures
- Secure redirects
- Callback verification
This affects systems running behind:
- CDN layers
- Reverse proxies
- API gateways
- Routing middleware
- Load balancers
Each layer may apply its own parsing rules.
That complexity explains why encoding bugs become notoriously difficult inside enterprise environments.
Frontend vs Backend Encoding Conflicts
Frontend frameworks usually encode URLs automatically. Problems begin when backend systems attempt to reprocess already encoded data.
For example, JavaScript applications commonly use:
encodeURIComponent()
Meanwhile PHP backends may apply:
urlencode()
again during request handling.
This creates accidental Double Encoding.
Different frameworks also interpret reserved characters differently.
A React router might preserve slashes while an API router encodes them. Suddenly dynamic routes fail only under specific conditions.
Legacy systems increase the risk further.
Older applications built on:
- Apache
- Nginx
- Microsoft IIS
sometimes rely on outdated parsing behavior incompatible with modern UTF-8 standards.
Browser compatibility also matters more than many people realize. Different browsers occasionally normalize URLs differently before sending requests.
That inconsistency creates edge-case bugs that appear impossible to reproduce consistently.
Why Manual URL Construction Is Dangerous
One of the fastest ways to create encoding issues is through raw string concatenation.
Developers often build URLs manually because it feels simple during development.
const url = "/products?search=" + userInput;
The code works fine until a customer searches for:
4K TV & Soundbar
Now the ampersand breaks the parameter structure entirely.
Using Native Encoding Functions eliminates this risk.
Modern languages already provide safe utilities:
| Language | Safe Encoding Function |
|---|---|
| JavaScript | encodeURIComponent() |
| PHP | rawurlencode() |
| Python | urllib.parse.quote() |
| Java | URLEncoder.encode() |
These tools follow established encoding standards instead of relying on fragile assumptions.
Good engineering teams avoid reinventing encoding logic manually.
Advanced Troubleshooting for Persistent Encoding Errors
Some encoding bugs disappear instantly after proper encoding fixes. Others evolve into nightmares.
Persistent issues usually involve multiple systems interacting together.
A request may travel through:
- Browser
- CDN
- WAF
- Load balancer
- Reverse proxy
- Backend middleware
- Microservice APIs
- Database layer
Each stage can transform or normalize URL data differently.
That’s why advanced debugging often focuses on tracing the full Encoding Pipeline and Decoding Pipeline step by step.
Experienced engineers inspect:
- HTTP headers
- Payload structures
- Routing middleware
- Character encoding settings
- Proxy rewrite rules
- Byte-level transformations
This process becomes especially important inside Distributed Systems where dozens of services communicate simultaneously.
Sometimes the real issue has nothing to do with encoding functions themselves. The root cause may involve hidden control characters copied from external systems or malformed data stored inside databases.
These subtle problems can survive for years unnoticed.
Best Practices to Prevent URL Encoder Spell Mistakes
The best solution is prevention.
Strong engineering teams standardize encoding rules early instead of fixing problems later under pressure.
One of the smartest practices involves enforcing UTF-8 consistently across the entire infrastructure stack.
That includes:
- Frontend applications
- APIs
- Databases
- Proxy servers
- Middleware
- HTTP headers
Mixed encoding standards create unpredictable behavior quickly.
Automated testing also matters enormously.
Good teams implement:
- Unit Testing
- Integration Testing
- URL validation checks
- Automated redirect testing
- API endpoint verification
inside CI/CD workflows.
This catches malformed URLs before deployment reaches production systems.
Monitoring matters too.
Error monitoring platforms should track:
- 400 responses
- Routing failures
- Invalid requests
- Decoding exceptions
- Redirect loops
Catching encoding problems early prevents cascading failures later.
The Role of URL Encoding in Secure Backend Development
Encoding is not just a formatting concern. It also plays a serious security role.
Improper URL handling can expose systems to:
- Injection attacks
- Open redirect vulnerabilities
- Path traversal exploits
- Request smuggling issues
Attackers frequently abuse malformed encoding to bypass validation layers.
For example, recursive encoding tricks may confuse security filters into approving dangerous payloads.
That’s why modern Secure Backend Development practices emphasize strict endpoint validation and deterministic URL handling.
A robust system should:
- Normalize URLs consistently
- Reject malformed hex values
- Validate query payloads
- Block invalid byte structures
- Sanitize unsafe characters
Security teams often combine encoding validation with firewall rules inside CDN and WAF layers.
This creates multiple layers of protection throughout the request lifecycle.
Tools That Help Detect and Fix Encoding Problems
Modern debugging tools make encoding analysis much easier than it used to be.
Chrome Developer Tools remains one of the most practical options because it exposes live network requests directly inside the browser.
For API workflows, developers frequently rely on Postman to inspect:
- Query parameters
- Encoded payloads
- Header behavior
- Redirect responses
Monitoring platforms like Datadog and Sentry help surface recurring encoding anomalies inside production environments.
SEO specialists also use crawling tools during technical audits to identify:
- Broken links
- Invalid redirects
- Duplicate encoded URLs
- Crawl path inefficiencies
The combination of development monitoring and SEO analysis creates a much clearer picture of overall URL health.
Long-Term Maintenance for Stable URL Architecture
Encoding stability is not a one-time task. It requires ongoing maintenance.
As applications grow, routing logic becomes more complex. New APIs appear. Frontend frameworks evolve. Third-party integrations introduce new parameter structures.
Without consistent governance, encoding drift slowly spreads across the architecture.
Successful teams create internal standards for:
- URL routing
- Query string formatting
- Parameter validation
- Redirect behavior
- API payload structure
This reduces inconsistency across engineering teams.
Documentation also helps more than people expect. Clear rules around Deterministic URL Structure prevent accidental deviations during rapid development cycles.
The goal is not merely avoiding errors. The real objective is building resilient systems that remain stable as infrastructure scales.
Final Thoughts on URL Encoder Spell Mistake Problems
A url encoder spellmistake may sound minor at first glance. In reality, encoding errors sit at the intersection of Software Engineering, networking, SEO, security, and backend architecture.
Modern websites rely on clean URLs for nearly everything:
- API routing
- Search indexing
- Authentication
- Analytics
- Dynamic content delivery
- Deep linking
- Web performance
When encoding breaks, systems stop communicating properly.
The frustrating part is that these failures often appear random. A URL works in one browser yet fails inside another environment. One API request succeeds while another returns a mysterious 404 Not Found or 400 Bad Request.
Underneath those symptoms usually sits the same root issue: inconsistent encoding logic.
Teams that treat URL handling seriously tend to build more reliable systems overall. Their applications route more predictably, scale more cleanly, and perform better under pressure.
In a world powered by APIs, distributed applications, and global internet infrastructure, proper URL Encoding is no longer optional. It’s foundational.
Read more knowledgeable blogs on Pun Zola

Jackson Pearson is a creative humor writer known for crafting clever puns and clean, engaging jokes. Through his blog, he brings lighthearted fun to everyday life, offering readers smart wordplay, relatable humor, and a warm, welcoming voice that makes each visit enjoyable.



